Haben Sie heute schon nach einer bestimmten Datei gesucht? Einem Angebot aus dem Vorjahr, einer technischen Richtlinie oder der Antwort auf eine knifflige Kundenfrage?
Laut einer bekannten Studie des McKinsey Global Institute verbringen Wissensarbeiter im Schnitt rund 1,9 Stunden pro Tag – das sind knapp 20 % der gesamten Arbeitszeit – allein mit der Suche und dem Zusammentragen von internen Informationen. Für deutsche Unternehmen im Mittelstand bedeutet das jedes Jahr einen immensen Verlust an Produktivität und wertvoller Zeit.
Die Lösung für dieses Problem liegt nicht in einer noch komplexeren Ordnerstruktur oder in regelmäßigen Aufräum-Appellen. Sie liegt in einer innovativen Technologie namens Retrieval-Augmented Generation (RAG). Mit einer maßgeschneiderten RAG-Pipeline im Mittelstand machen Sie Ihr verstreutes Firmenwissen über eine einfache, intuitive Chat-Schnittstelle sofort nutzbar.
Das Problem: Warum klassische Suchfunktionen im Unternehmen versagen
In fast jedem Betrieb wächst die Datenmenge täglich. Dokumente liegen verstreut auf lokalen Netzlaufwerken, in Cloud-Speichern wie Sharepoint, im E-Mail-Postfach, im Wiki oder im CRM-System.
Wer hier nach Informationen sucht, stößt mit der klassischen Stichwortsuche schnell an Grenzen. Suchbegriffe müssen exakt übereinstimmen, Synonyme werden ignoriert, und das System versteht den Kontext Ihrer Suchanfrage nicht.
Das führt dazu, dass Mitarbeiter wertvolle Stunden mit dem Durchforsten von irrelevanten Suchtreffern verbringen, anstatt produktiv zu arbeiten. Genau hier setzt die RAG-Technologie an. Sie verknüpft die Sprachfähigkeiten moderner Künstlicher Intelligenz mit dem gezielten, sicheren Zugriff auf Ihre internen Datenquellen.
Warum KI allein nicht reicht: Die Notwendigkeit von RAG
Ein modernes Large Language Model (LLM) wie GPT-4 oder Gemeni ist faszinierend intelligent, hat aber ein entscheidendes Problem: Es kennt Ihr Unternehmen nicht. Es weiß nichts über Ihre spezifischen Produkte, Ihre internen Prozesse oder Ihre individuellen Kundenvereinbarungen.
Wenn Sie ein solches Modell direkt nach internen Details fragen, erfindet es im schlimmsten Fall plausible, aber falsche Antworten – ein Phänomen, das Experten als „Halluzination“ bezeichnen.
Die Retrieval-Augmented Generation (RAG) löst dieses Problem elegant:
- Der Nutzer stellt eine Frage an das System.
- 2. Ein vorgeschalteter Suchschritt (Retrieval) sucht in Ihren Dokumenten nach den relevantesten Textabschnitten.
- 3. Die gefundenen Fakten werden zusammen mit der Frage an die KI übergeben.
- 4. Die KI formuliert eine präzise Antwort – ausschließlich basierend auf den bereitgestellten Dokumenten.
Sie fungiert also wie ein intelligenter Assistent, der vor der Antwort schnell die passenden Akten heraussucht und zusammenfasst.
Blick hinter die Kulissen: So funktioniert eine RAG-Pipeline im Mittelstand
Um zu verstehen, wie eine RAG-Pipeline in Ihrem Unternehmen arbeitet, werfen wir einen Blick auf ein reales Beispiel aus unseren Systemen bei cyberEiche. Eine funktionierende Pipeline lässt sich in drei wesentliche Phasen unterteilen: das Crawling, das Chunking und die Ingestion.
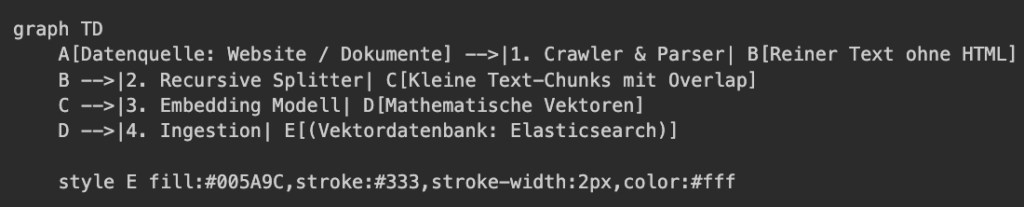
Schritt 1: Das intelligente Crawling (Datenerfassung)
Zuerst muss die KI Zugriff auf die Daten erhalten. In unserem Beispiel lassen wir einen spezialisierten Crawler über unsere eigene Website laufen:
Unter der Haube nutzen wir dafür hochmoderne Tools wie den `RecursiveUrlLoader` aus dem LangChain-Framework. Der Crawler startet auf der Homepage, erfasst alle internen Verweise (z. B. auf `/contact` oder `/services`) und lädt die Inhalte rekursiv herunter.
Damit die KI nicht durch unnötigen Code abgelenkt wird, filtert ein Parser (`BeautifulSoup` kombiniert mit `lxml`) das HTML-Grundgerüst. Er entfernt Stylesheets, Skripte und Navigationsleisten, sodass am Ende nur der reine, relevante Text übrig bleibt.
Schritt 2: Das präzise Chunking (Textaufteilung)
Ein langes Handbuch oder eine komplette Website kann nicht als ein einziger Block an die KI gesendet werden. Das wäre langsam, teuer und ineffizient. Deshalb wird der Text in kleine, handliche Abschnitte unterteilt, sogenannte Chunks.

Bei cyberEiche setzen wir hierbei auf den `RecursiveCharacterTextSplitter`. In unserer Konfiguration teilen wir Texte in Abschnitte von 1.000 Zeichen (Chunk Size) auf.
Ein entscheidendes Detail ist der **Chunk Overlap von 100 Zeichen**. Das bedeutet, dass sich aufeinanderfolgende Abschnitte am Anfang und Ende leicht überschneiden. Dadurch stellen wir sicher, dass kein wichtiger Satz genau in der Mitte zerschnitten wird und der inhaltliche Zusammenhang an den Übergängen erhalten bleibt.
Schritt 3: Vektor-Embeddings und Ingestion (Speicherung)
Damit ein Computer die Bedeutung von Texten blitzschnell vergleichen kann, müssen wir sie in Mathematik übersetzen.

Jeder Textabschnitt wird an ein sogenanntes Embedding-Modell (in unserem Fall `all-MiniLM-L6-v2`) gesendet. Dieses Modell verwandelt den Text in ein Vektor-Embedding – ein mathematisches Array aus 384 Dezimalzahlen, das die semantische Bedeutung des Textes repräsentiert.
Diese Vektoren werden zusammen mit dem Originaltext und Metadaten (wie der Quell-URL und dem Titel) in einer professionellen Suchdatenbank wie Elasticsearch gespeichert. In unserer Praxis organisieren wir diese Daten in separaten Arbeitsbereichen (z. B. `test_workspace`), um Zugriffsrechte sauber zu trennen.
Wie sieht das Ergebnis aus? Ein Blick in die Vektordatenbank
Nachdem der Ingestion-Prozess abgeschlossen ist, befinden sich die Daten sauber strukturiert in der Datenbank. Hier sind drei typische Beispiele für Textabschnitte (Chunks), wie sie nach dem Parsing- und Chunking-Prozess in unserer Elasticsearch-Datenbank abgelegt sind:
🔹 CHUNK #1: Übersicht der Dienstleistungen
Quelle: `https://cybereiche.de`
Inhalt:
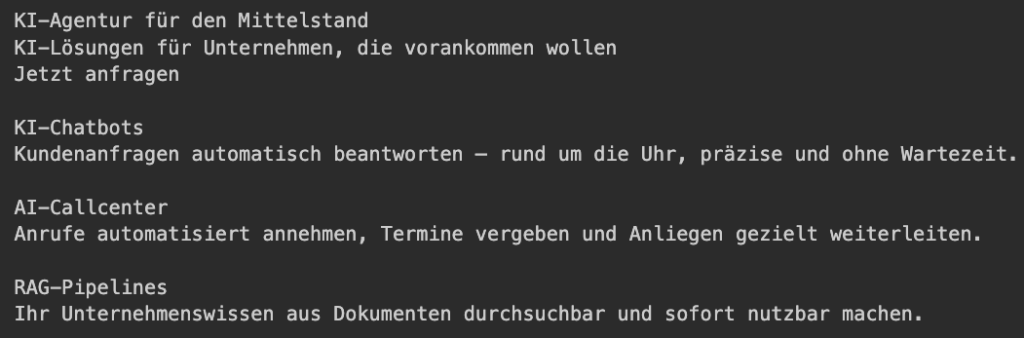
🔹 CHUNK #2: Über uns & Fokusbranchen
Quelle: `https://cybereiche.de`
Inhalt:
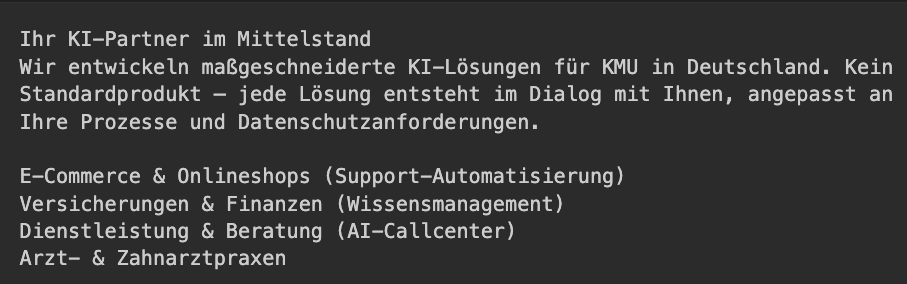
🔹 CHUNK #3: Kontakt & Footer-Informationen
Quelle: `https://cybereiche.de/contact/`
Inhalt:
Der Abfrage-Zyklus: So findet die KI die richtige Antwort
Wenn ein Mitarbeiter nun dem System eine Frage stellt, beginnt die Magie der semantischen Suche. Nehmen wir an, die Frage lautet: „Welche Dienstleistungen bietet cyberEiche an?“
- Vektorisierung: Das System wandelt die Frage des Nutzers mithilfe desselben Embedding-Modells in einen Suchvektor um.
- Ähnlichkeitssuche: Elasticsearch führt eine hocheffiziente Ähnlichkeitssuche (k-Nearest Neighbors / kNN) durch. Es berechnet den mathematischen Abstand zwischen dem Fragevektor und allen gespeicherten Abschnitten.
- Treffer ermitteln: Das System stellt fest, dass **Chunk #1** (der die Dienstleistungen auflistet) die größte mathematische Ähnlichkeit zur Frage aufweist, und ruft diesen Text ab.
- Prompt-Strukturierung: Die RAG-Software baut im Hintergrund automatisch folgenden strukturierten Befehl für das Sprachmodell (z. B. ChatGPT) zusammen:
- Generierung: Das Sprachmodell liest diesen Prompt und formuliert eine flüssige, absolut korrekte Antwort: *“Basierend auf den bereitgestellten Informationen bietet cyberEiche maßgeschneiderte KI-Lösungen für den Mittelstand an. Dazu gehören KI-Chatbots für den Kundenservice, automatisierte AI-Callcenter für die Telefonannahme sowie RAG-Pipelines zur intelligenten Erschließung von Unternehmensdaten.“*
Der große Vorteil: Die Antwort ist vollständig durch Fakten gedeckt. Es gibt kein Erfinden von Dienstleistungen, und das System nennt auf Wunsch die genaue Quelle.
Konkrete Anwendungsfälle: RAG im Abteilungs-Check
Wie sieht der Einsatz einer RAG-Pipeline in den unterschiedlichen Abteilungen eines mittelständischen Unternehmens aus? Drei Beispiele verdeutlichen den enormen Praxisnutzen:
1. Kundenservice & Support-Automatisierung
Ihr Support-Team erhält täglich ähnliche Fragen zu Produktfunktionen, Lieferzeiten oder Reklamationsabläufen. Ein mit einer RAG-Pipeline verknüpfter KI-Chatbot liest alle Produkthandbücher und FAQ-Listen ein. Er beantwortet Kundenfragen rund um die Uhr präzise, entlastet Ihr Team und verweist bei komplexen Fällen direkt auf das passende Ticket-System.
2. HR & Mitarbeiter-Onboarding
Neue Mitarbeiter verbringen in den ersten Wochen viel Zeit damit, sich durch interne Wikis und PDF-Leitfäden zu kämpfen. Ein interner RAG-Assistent beantwortet Fragen wie „Wie reiche ich eine Reisekostenabrechnung ein?“ oder „Wo finde ich das Urlaubsformular?“ sofort. Er liefert direkt den Link zum Dokument mit – das spart wertvolle Zeit in der Einarbeitung.
3. Vertrieb & Technische Dokumentation
Vertriebsmitarbeiter müssen bei Angebotserstellungen oft komplexe Spezifikationen prüfen. Statt hunderte Seiten von technischen Dokumenten manuell zu durchsuchen, fragt der Vertriebler einfach die KI: „Welche maximale Betriebstemperatur ist für Baureihe X zugelassen?“. Das System liefert die Antwort in Sekunden, inklusive Quellennachweis und Seitenzahl im Original-PDF.
Was eine gute KI-Lösung können muss
Wenn Sie eine RAG-Pipeline im eigenen Unternehmen einführen möchten, sollten Sie auf folgende Qualitätskriterien achten:
- Präzises Parsing: Das System muss Tabellen, Grafiken und PDFs fehlerfrei einlesen können.
- Hybride Suche: Eine Kombination aus Vektorsuche (für die Bedeutung) und klassischer Keyword-Suche (für exakte Artikelnummern oder Eigennamen) liefert die besten Ergebnisse.
- Benutzerfreundliches UI: Die Suchmaske muss für jeden Mitarbeiter ohne Schulung direkt verständlich sein – idealerweise als einfacher Chat im Browser oder integriert in Teams oder Slack.
- Skalierbarkeit: Eine Vektordatenbank wie Elasticsearch wächst problemlos mit Millionen von Dokumenten mit, ohne an Geschwindigkeit zu verlieren.
Datenschutz-Grundverordnung (DSGVO) & Compliance: Sicherheit geht vor
Gerade für deutsche Unternehmen im Mittelstand ist das Thema Datenschutz ein zentrales Kriterium. Niemand möchte, dass sensible interne Verträge, Kundendaten oder Produktpatente auf Servern außerhalb Europas landen oder zum Training öffentlicher KI-Modelle genutzt werden.
Eine professionelle RAG-Pipeline im Mittelstand muss daher höchsten Sicherheitsansprüchen genügen:
- Europäische Server: Die gesamte Infrastruktur – von der Vektordatenbank Elasticsearch bis hin zu den Sprachmodellen – wird auf Servern innerhalb der EU betrieben.
- Kein Modelltraining mit Ihren Daten: Ihre Dokumente werden ausschließlich temporär als Kontext an das Modell übermittelt. Es findet kein dauerhaftes Abspeichern oder Training auf Seiten des KI-Anbieters statt.
- Feingranulare Rechteverwaltung: Das System stellt sicher, dass Mitarbeiter nur Antworten aus Dokumenten erhalten, für die sie auch die entsprechenden Leserechte besitzen.
Damit ist die Lösung vollständig konform mit der Datenschutz-Grundverordnung (DSGVO) und kann bedenkenlos im Unternehmensalltag eingesetzt werden.
Fazit: Unternehmenswissen aktivieren und Arbeitszeit sparen
Das Suchen nach Informationen in verstaubten Ordnerstrukturen gehört der Vergangenheit an. Mit einer eigenen RAG-Pipeline verwandeln Sie das passive, verstreute Wissen Ihrer Mitarbeiter in eine aktive, sofort nutzbare Ressource. Sie steigern die Effizienz im Team, verkürzen Reaktionszeiten im Support und erleichtern das Onboarding neuer Kollegen erheblich.
Nächste Schritte
Möchten Sie wissen, wie eine RAG-Pipeline mit Ihren eigenen Unternehmensdaten aussehen könnte? Machen Sie jetzt unseren kostenlosen KI-Readiness-Check oder vereinbaren Sie ein unverbindliches Erstgespräch.
Besuchen Sie uns auf cybereiche.de und lassen Sie uns gemeinsam Ihr Unternehmenswissen aktivieren!